检查点是一个数据库事件,它把修改数据从高速缓存写入磁盘,并更新控制文件和数据文件。
检查点分为三类:
1)局部检查点:单个实例执行数据库所有数据文件的一个检查点操作,属于此实例的全部脏缓存区写入数据文件。
触发命令:
svmrgrl>alter system checkpoint local;
这条命令显示的触发一个局部检查点。
2)全局检查点:所有实例(对应并行数据服务器)执行数据库所有所有数据文件的一个检查点操作,属于此实例的全部脏缓存区写入数据文件。
触发命令
svrmgrl>alter system checkpoint global;
这条命令显示的触发一个全局检查点。
3)文件检查点:所有实例需要执行数据文件集的一个检查点操作,如使用热备份命令alter tablespace USERS begin backup,或表空间脱机命令alter tablespace USERS offline,将执行属于USERS表空间的所有数据文件的一个检查点操作。
检查点处理步骤:
1)获取实例状态队列:实例状态队列是在实例状态转变时获得,ORACLE获得此队列以保证检查点执行期间,数据库处于打开状态;
2)获取当前检查点信息:获取检查点记录信息的结构,此结构包括当前检查点时间、活动线程、进行检查点处理的当前线程、日志文件中恢复截止点的地址信息;
3)缓存区标识:标识所有脏缓存区,当检查点找到一个脏缓存区就将其标识为需进行刷新,标识的脏缓存区由系统进程DBWR进行写操作,将脏缓存区的内容写入数据文件;
4)脏缓存区刷新:DBWR进程将所有脏缓存区写入磁盘后,设置一标志,标识已完成脏缓存区至磁盘的写入操作。系统进程LGWR与CKPT进程将继续进行检查,直至DBWR进程结束为止;
5)更新控制文件与数据文件。
注:控制文件与数据文件头包含检查点结构信息。
在两种情况下,文件头中的检查点信息(获取当前检查点信息时)将不做更新:
1)数据文件不处于热备份方式,此时ORACLE将不知道操作系统将何时读文件头,而备份拷贝在拷贝开始时必须具有检查点SCN;
ORACLE在数据文件头中保留一个检查点的记数器,在正常操作中保证使用数据文件的当前版本,在恢复时防止恢复数据文件的错误版本;即使在热备份方式下,计数器依然是递增的;每个数据文件的检查点计数器,也保留在控制文件相对应数据文件项中。
2)检查SCN小于文件头中的检查点SCN的时候,这表明由检查点产生的改动已经写到磁盘上,在执行全局检查点的处理过程中,如果一个热备份快速检查点在更新文件头时,则可能发生此种情况。应该注意的是,ORACLE是在实际进行检查点处理的大量工作之前捕获检查SCN的,并且很有可能被一条象热备份命令alter tablespace USERS begin backup进行快速检查点处理时的命令打断。
ORACLE在进行数据文件更新之前,将验证其数据一致性,当验证完成,即更新数据文件头以反映当前检查点的情况;未经验证的数据文件与写入时出现错误的数据文件都被忽略;如果日志文件被覆盖,则这个文件可能需要进行介质恢复,在这种情况下,ORACLE系统进程DBWR将此数据文件脱机。
检 查点算法描述:
脏缓存区用一个新队列链接,称为检查点队列。对缓存区的每一个改动,都有一个与其相关的重做值。检查点队列包含脏的日志缓存区,这些缓存区按照它们在日志文件中的位置排序,即在检查点队列中,缓存区按照它们的低重做值进行排序。需要注意的是,由于缓存区是依照第一次变脏的次序链接到队列中的,所以,如果在缓存区写出之前对它有另外的改动,链接不能进行相应变更,缓存区一旦被链接到检查点队列,它就停留在此位置,直到将它被写出为止。
ORACLE系统进程DBWR在响应检查点请求时,按照这个队列的低重做值的升序写出缓存区。每个检查点请求指定一个重做值,一旦DBWR写出的缓存区重做值等于或大雨检查点的重做值,检查点处理即完成,并将记录到控制文件与数据文件。
由于检查点队列上的缓存区按照低重做值进行排序,而DBWR也按照低重做值顺序写出检查点缓存区,故可能有多个检查点请求处于活动状态,当DBWR写出缓存区时,检查位于检查点队列前端的缓存区重做值与检查点重做值的一致性,如果重做值小于检查点队列前缓存区的低重做值的所有检查点请求,即可表示处理完成。当存在未完成的活动检查点请求时,DBWR继续写出检查点缓存区。
算法特点:
1)DBWR能确切的知道为满足检查点请求需要写那些缓存区;
2)在每次进行检查点写时保证指向完成最早的(具有最低重做值的)检查点;
3)根据检查点重做值可以区别多个检查点请求,然后按照它们的顺序完成处理。
1.检查点(Checkpoint)的本质
许多文档把Checkpint描述得非常复杂,为我们正确理解检查点带来了障碍,结果现在检查点变成了一个非常复杂的问题。实际上,检查点只是一个数据库事件,它存在的根本意义在于减少崩溃恢复(Crash Recovery)时间。
当修改数据时,需要首先将数据读入内存中(Buffer Cache),修改数据的同时,Oracle会记录重做信息(Redo)用于恢复。因为有了重做信息的存在,Oracle不需要在提交时立即将变化的数据写回磁盘(立即写的效率会很低),重做(Redo)的存在也正是为了在数据库崩溃之后,数据就可以恢复。
最常见的情况,数据库可以因为断电而Crash,那么内存中修改过的、尚未写入文件的数据将会丢失。在下一次数据库启动之后,Oracle可以通过重做日志(Redo)进行事务重演,也就是进行前滚,将数据库恢复到崩溃之前的状态,然后数据库可以打开提供使用,之后Oracle可以将未提交的数据进行回滚。
在这个过程中,通常大家最关心的是数据库要经历多久才能打开。也就是需要读取多少重做日志才能完成前滚。当然用户希望这个时间越短越好,Oracle也正是通过各种手段在不断优化这个过程,缩短恢复时间。
检查点的存在就是为了缩短这个恢复时间。
当检查点发生时(此时的SCN被称为CheckPoint SCN),Oracle会通知DBWR进程,把修改过的数据,也就是Checkpoint SCN之前的脏数据(Dirty Data)从Buffer Cache写入磁盘,当写入完成之后,CKPT进程更新控制文件和数据文件头,记录检查点信息,标识变更。
Oracle SCN的相关知识可以参考我的另外一篇文章:DBA入门之认识Oracle SCN(System Change Number)
Checkpoint SCN可以从数据库中查询得到:
SQL> select file#,CHECKPOINT_CHANGE#,to_char(CHECKPOINT_TIME,'yyyy-mm-dd hh24:mi:ss') cpt from v$datafile;
FILE# CHECKPOINT_CHANGE# CPT
---------- ------------------ -------------------
1 913306 2011-11-16 16:06:06
2 913306 2011-11-16 16:06:06
3 913306 2011-11-16 16:06:06
4 913306 2011-11-16 16:06:06
SQL> select dbid,CHECKPOINT_CHANGE# from v$database;
DBID CHECKPOINT_CHANGE#
---------- ------------------
1294662348 913306
在检查点完成之后,此检查点之前修改过的数据都已经写回磁盘,重做日志文件中的相应重做记录对于崩溃/实例恢复不再有用。
下图标记了3个日志组,假定在T1时间点,数据库完成并记录了最后一次检查点,在T2时刻数据库Crash。那么在下次数据库启动时,T1时间点之前的Redo不再需要进行恢复,Oracle需要重新应用的就是时间点T1至T2之间数据库生成的重做日志(Redo)。
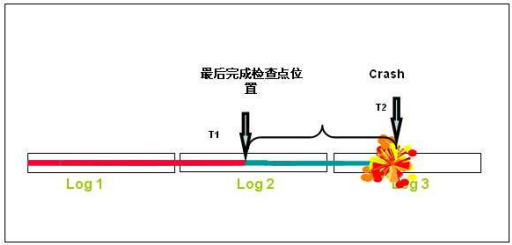
上图可以很轻易地看出来,检查点的频率对于数据库的恢复时间具有极大的影响,如果检查点的频率高,那么恢复时需要应用的重做日志就相对得少,检查时间就可以缩短。然而,需要注意的是,数据库内部操作的相对性极强,国语平凡的检查点同样会带来性能问题,尤其是更新频繁的数据库。所以数据库的优化是一个系统工程,不能草率。
更进一步可以知道,如果Oracle可以在性能允许的情况下,使得检查点的SCN主键逼近Redo的最新更新,那么最终可以获得一个最佳平衡点,使得Oracle可以最大化地减少恢复时间。
为了实现这个目标,Oracle在不同版本中一直在改进检查点的算法。



 |手机版|小黑屋|重庆思庄Oracle、Redhat认证学习论坛
( 渝ICP备12004239号-4 )
|手机版|小黑屋|重庆思庄Oracle、Redhat认证学习论坛
( 渝ICP备12004239号-4 )


 发表于 2012-12-21 18:59:30
发表于 2012-12-21 18:59:30


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 收藏
收藏 支持
支持 反对
反对 楼主
楼主

